Availability and Consistency
Availability and consistency are very important parts of system design, and based on our decision whether the system needs to be highly available or highly consistent, the entire design can be affected. Based on the requirements, we should understand how the system should behave when there is a network failure or node failure. Before diving deep into this, let's first understand the meaning of some terms:
-
Availability: Availability means a system should be available at all times, even in cases of node failures, network failures, etc. This is very critical for business continuity as a system that goes down from time to time may affect business or other systems as well. Example: We all use social media every day. Social media not only provides us with the latest updates of people around us, but it is also a great source for businesses to sell their products to potential customers via ads. These businesses pay money to social media platforms to run ads and, in return, they get business. Imagine a social media platform fails; the platform won't be able to receive money from these businesses to run their ads. Businesses won't be able to sell their products as the platform is down. And in turn, there is a huge loss of revenue during this time.
-
Consistency: Consistency means a system should be consistent at all times. Either the system should provide the latest data, or the system should return an error. Example: You might have used internet banking. Imagine you did a transaction of X amount to someone. The money got deducted from your account, but it is not visible in the account of the person you sent it to. There may be several causes to this: a network failure, a server failure, etc. At this point, the system is inconsistent. So consistency plays a vital role here. It would be better if the system had returned an error instead of a successful transaction.
-
Partition Tolerance: Partition tolerance means whenever there is a partition in the system (server failure, network failure, etc.), it should continue to work and should not crash. It may be working in a degraded mode where some services are working, and some are not working, instead of complete unavailability. Consider the bank example where we are transferring money from Account A to Account B. Due to some reason, there is an issue with the transfer. The issue can be that the transfer microservice is down. So instead of a complete system shutdown, some features should still work, like inquiring about the balance.
CAP Theorem
Consistency, Availability, and Partition Tolerance (CAP) theorem states that a system can only have two of the three properties defined. A system can be:
- Consistent and Available (CA)
- Available and Partition Tolerance (AP)
- Consistent and Partition Tolerance (CP)
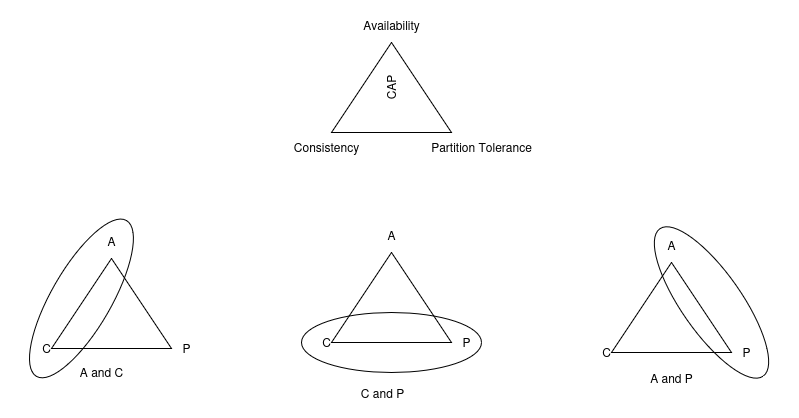
Let's see each of these properties in detail.
Consistent and Available
A system that is consistent and available assumes that there will never be a network partition. This is only possible in single-node systems or a monolithic application. These kinds of systems are unrealistic in the case of distributed architecture. In the real world, network-related issues do happen, and it will make the system prone to complete failures.
As an example, imagine a single-node small e-commerce store:
- Availability: The system will always be able to respond to user requests as long as the server is running.
- Consistency: If a customer adds some data to the cart, it will always reflect the latest data to the user. So it is consistent.
- Partition Tolerance: Since this is a single-node system, in case the server fails, the entire application will fail as it does not have any partition tolerance.
Available and Partition Tolerance
This defines that the system will always be available even if there is an incident of network partition. However, there is a catch here. The responses we are getting may not be the latest ones. The reason is, there are some node failures due to which the latest state is not updated across all the nodes.
As an example, consider a social media platform like Instagram:
- Availability: In case there is a network partition between some servers, users can still like posts and see like counts. There may be a delay in getting the latest posts, but the system is still functional.
- Partition Tolerance: The system is still functional even in cases of some node failures or network failures.
- Consistency: The system is not consistent here. Some users may see 10 likes on a post, while others may see 8 likes as updates are not propagated to all the servers.
Consistent and Partition Tolerance
This defines that the system will always be consistent even if there is a network partition. The system will always return the latest data. However, availability may take a hit here.
As an example, consider a banking system where someone is trying to transfer money from account A to account B. This system will be consistent and make sure that if the money is deducted, it should be reflected in account B.
- Consistency: The system is consistent here. Users will always get the latest write. In an event of a server failure or a network failure, the system will return an error and will not allow initiating a transfer.
- Partition Tolerance: In the event of a network failure, the system will return an error and will block the transaction until the partition is resolved. This way, no inconsistencies will be originated.
- Availability: This system sacrifices availability as the transactions will be blocked until all partitions are resolved.
In practice, no system follows 100% AP or 100% CP. The systems in practice always establish a balance between availability and consistency. Though we have a consistent banking system (CP) that blocks transactions during a network partition, it can still allow balance inquiries as they do not modify any data. Similarly, a social media platform (AP) allows users to interact with posts during a network failure, but like counts may be inconsistent. However, they do have consistent operations that these systems may block, like profile updates, authentication, etc., until the partition failure gets resolved.
PACELC Theorem
The PACELC theorem is an extension of the CAP theorem that involves more terms to provide deeper insights into trade-offs. It states that if there is a Partition, then a distributed system must choose between Availability or Consistency, and Else it must choose between Latency or Consistency. These words, in short, make up PACELC.

The major addition to this theorem is the trade-off between latency and consistency. If the system is consistent, latency will take a hit. If the system is fast and provides low latency, consistency will take a hit.
Some examples of latency and consistency trade-offs are as follows:
- Bank Transactions: Bank transactions need to be consistent, and the system waits until both debit and credit transactions are confirmed. This waiting guarantees no discrepancies but introduces latency.
- Online Video Streaming: While streaming a live video, platforms prioritize low latency to ensure viewers can see the stream with minimal delay.